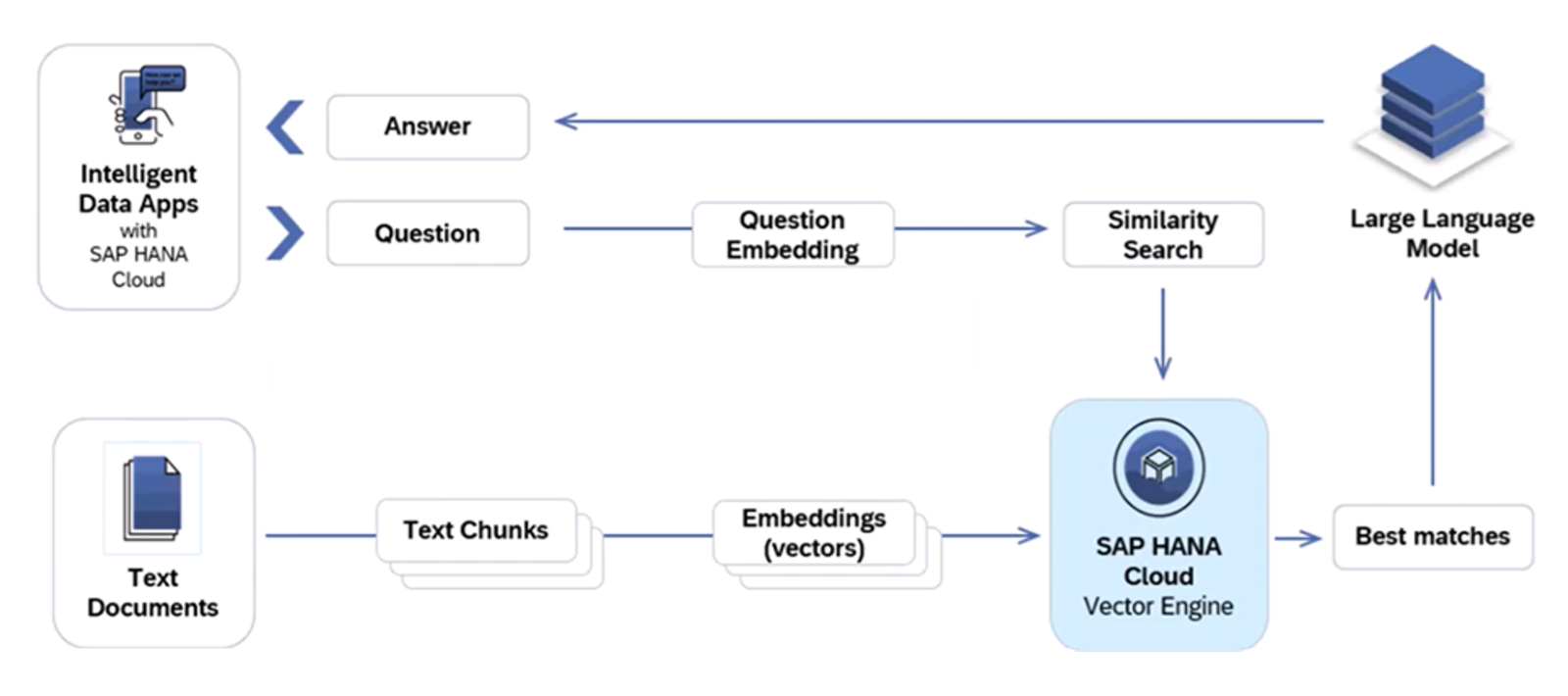
Vector-based RAG (2/2) Query Pipeline
1 Overview
Description
Retrieval-Augmented Generation (RAG) is a powerful technique that combines the strengths of retrieval-based and Large Language generative models (LLMs) to enhance the quality and relevance of generated content. Implementing a Vector Based RAG is a two step approach-
- Embedding Creation - Embeddings are the numerical vector representation of the knowledge segments. In this step, you convert knowledge base to vectors and store them in vector database. To have a better understanding of this topic and related best practices, it is recommended to go through Vector Embedding(1/1) part in this series.
- Query Pipeline - In this step we leverage the vector representation of the knowledge base and augment the LLM context. To achieve this, first we convert the question into vector embedding and then perform similarity search in Vector database and fetch the best matches. Post that we leverage these best matches as augmented context along with prompt to LLM to generate a response for the user's question.
In this best practice we will focus on querying aspect when using RAG technique.